Atelier d’idéation
La transformation Métiers commence avec une I.D.E.A
Donnez une nouvelle envergure à votre entreprise – rencontrez nos directeurs et vice-présidents lors d’un atelier d’idéation dédié.
Cet article traite d'un élément de Synapse SQL : le pool SQL sans serveur. Les raisons pour lesquelles vous pouvez l'utiliser, l'architecture, le coût et la façon dont vous l'utilisez pour interroger des données dans différentes sources de stockage Azure.
Comme vous l’avez peut-être déjà remarqué, depuis le 3 décembre 2020, Azure Synapse Analytics est désormais disponible, le directeur de notre département Data Science & Analytics, Jonathan Scott en a donné un excellent aperçu dans son article à lire ici.
Bien qu’il existe de nombreuses nouvelles fonctionnalités qui sont déjà disponibles dans Synapse, nous avons choisi pour cet article de faire un focus sur Synapse SQL. Synapse SQL donne aux utilisateurs de l’espace de travail Azure Synapse Analytics la possibilité d’effectuer des analyses basées sur SQL à grande échelle. Nous verrons ici qu’il y a des nuances à utiliser cela d’un point de vue technique, ainsi qu’un potentiel d’ajustement substantiel du modèle de coût dans Azure en fonction des charges de travail SQL.
Synapse SQL propose deux modèles de consommation. Des Pools SQL dédiés, dans lesquels vous pouvez provisionner un pool par unité d’échelle, augmenter ou diminuer la capacité de service et le mettre en pause pendant les heures non opérationnelles. L’autre est un Pool SQL sans serveur, où vous n’avez pas besoin de provisionner un serveur, le pool se met à l’échelle automatiquement et vous consommez le service sur un modèle de coût à l’utilisation. Un espace de travail Synapse peut avoir plusieurs pools SQL dédiés mais un seul pool SQL sans serveur. Le type de ressource que vous utilisez est déterminé par le modèle de coût qui vous convient et qui correspond à vos besoins informatiques.
Nous allons examiner de plus près un élément de Synapse SQL : le pool SQL sans serveur. Les raisons pour lesquelles vous pouvez l’utiliser, l’architecture, le coût et la façon dont vous l’utilisez pour interroger des données dans différentes sources de stockage Azure.
Par défaut, chaque espace de travail Synapse que vous créez est fourni avec un pool SQL sans serveur par défaut. Dans Synapse Studio, sous Gérer> Pools SQL, vous verrez un pool appelé «Built-In»; il s’agit de votre pool SQL sans serveur, comme indiqué ci-dessous.
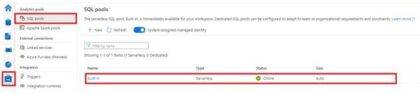
En raison de la nature du pool SQL sans serveur, il n’y a pas d’infrastructure à configurer ou de cluster à maintenir, il s’adapte automatiquement à vos besoins de charge et vous pouvez commencer à interroger les données stockées dans Azure Storage dès que vous avez créé un espace de travail Synapse.
Comme vous pouvez le constater, il existe de nombreux cas d’utilisation pour un pool SQL sans serveur, en voici quelques exemples :
En fin de compte, la décision d’utiliser le pool SQL sans serveur dépendra des cas d’utilisation individuels et d’une analyse coûts / avantages : Est-ce l’option optimale d’utiliser un pool SQL sans serveur ou une ressource telle que des pools SQL dédiés serait-elle un meilleur choix pour des charges de travail particulières ?
Le pool SQL sans serveur utilise une architecture évolutive pour distribuer le traitement sur plusieurs nœuds, comme des pools SQL dédiés. Et comme les pools SQL dédiés, le calcul et le stockage sont séparés les uns des autres, c’est ce qui permet au calcul d’évoluer indépendamment de vos données.
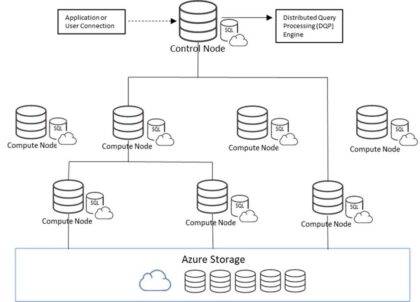
L’une des principales différences d’architecture entre les deux services Synapse SQL est que la puissance de calcul des pools SQL dédiés est déterminée par l’unité d’échelle provisionnée, appelée unités d’entrepôt de données (DWU), et les requêtes sont distribuées en parallèle sur les nœuds de calcul à l’aide d’un moteur de traitement massivement parallèle (MPP). Un pool SQL sans serveur, quant à lui, utilise un moteur DQP (Distributed Querying Processing) qui attribue des tâches aux nœuds de calcul pour terminer une requête. Dans le diagramme ci-dessous, une requête est transmise au nœud de contrôle central qui utilise DQP. Quatre nœuds de calcul étaient nécessaires pour terminer la requête en fonction du nombre de tâches déterminé par le moteur DQP. C’est ce qui permet au pool SQL sans serveur de s’adapter automatiquement à toute exigence de requête.
Le pool SQL sans serveur utilise un modèle de tarification par utilisation. Le coût est calculé par To de données traitées par vos requêtes. Ceci est différent des pools SQL dédiés où vous payez pour une ressource provisionnée à une échelle prédéterminée. Le prix du pool SQL sans serveur est approximativement de 4,32€ par To de données traitées, de sorte que les coûts peuvent rapidement augmenter si les requêtes traitées concernent de très grands ensembles de données de plusieurs To.
Si l’idée que les utilisateurs finaux exécutent involontairement des requêtes massives avec un modèle de coût par requête vous effraie, il existe un moyen de gérer les dépenses. La fonction de gestion des coûts de Synapse vous permet de définir des budgets sur le montant qui peut être dépensé sur une base quotidienne, hebdomadaire ou mensuelle, et peut être configurée via Synapse Studio ou via la procédure stockée dans T-SQL.
Pour configurer la gestion des budgets dans Synapse Studio, vous devez naviguer vers Gérer-> Pools SQL et cliquer sur l’icône Gestion des coûts pour le pool sans serveur «Intégré» (Built-in) comme indiqué ci-dessous.
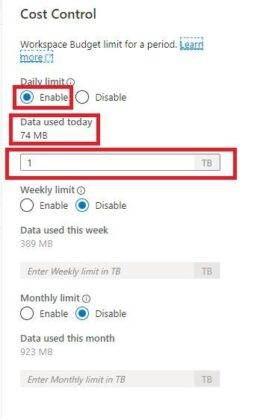
Cela fera apparaître l’écran de configuration Gestion des Coûts comme indiqué ci-dessous. Ici, les budgets peuvent être configurés en termes de To par jour, par semaine ou par mois. Vous obtenez également une vue des dépenses réelles en termes de quantité de données traitées. Cela peut être utile pour estimer quand les limites budgétaires sont sur le point d’être atteintes.
L’inconvénient de la fonctionnalité Gestion des Coûts est que les limites ne peuvent être configurées que pour un pool SQL sans serveur complet par espace de travail. Cela suggère que si vous souhaitez un contrôle plus détaillé des coûts, vous devrez créer plusieurs espaces de travail pour gérer les coûts par service équipe, etc.
Avec le pool SQL sans serveur, vous pouvez interroger les données stockées dans ADLS Gen2 (Data Lake), Azure Blob Storage, Cosmos DB et Spark Tables à l’aide de T-SQL. Les formats de fichiers pris en charge incluent Parquet, CSV et JSON.
Vous disposez d’un point de terminaison pour pool SQL sans serveur lorsque vous créez un espace de travail Synapse et un langage T-SQL familier. Par conséquent, tout outil client qui peut établir une connexion SQL TDS peut se connecter et interroger des données à l’aide du pool SQL sans serveur. Cela inclut Synapse Studio, SQL Server Management Studio, Azure Data Studio, Azure Analysis Services et Power BI.
La fonction T-SQL OPENROWSET est disponible pour que vous puissiez interroger votre Data Lake principal (associé à votre espace de travail Synapse), ou des sources de données externes de stockage Azure. Des fonctionnalités utiles telles que l’inférence automatique de schéma vous permettent de lire des fichiers Parquet sans avoir à déclarer les noms de colonnes dans votre requête. Vous trouverez ci-dessous un exemple de requête qui interroge l’ensemble de données New York Taxi accessible au public.

Autre fonctionnalité intéressante, c’est la possibilité de lire des tables Spark à l’aide de la syntaxe T-SQL sans avoir besoin de provisionner un cluster Spark, de payer pour la ressource réservée, d’attendre son démarrage, puis d’exécuter une requête SQL. Avec le pool SQL sans serveur, vous pouvez interroger une table Spark en quelques secondes plutôt qu’en quelques minutes, et avec la connectivité à Power BI, cela ouvre une toute nouvelle et puissante possibilité d’analyse rapide et de visualisation de vos données.
Il y a des limites au T-SQL que vous pouvez utiliser avec le pool SQL sans serveur. Pour plus de détails sur le T-SQL pris en charge par le pool SQL sans serveur, veuillez consulter l’article Microsoft suivant ici.
